研发项目总描述文档是研发过程中重要的一环。 不仅研发团队可以在开发过程中用它随时回顾进程,设计下一步走向,即使在项目结束后,接手团队仍然可以延续过程。项目描述文档可以让大的团队保持同步。特别是在开发复杂、大范围系统的项目中,作用至关重要,项目组织者必须搞好。下面我们提供一套根绝实际项目编写的通用项目文档模板。稍加修改,可适用于大部分技术项目。

研发项目总描述文档是研发过程中重要的一环。 不仅研发团队可以在开发过程中用它随时回顾进程,设计下一步走向,即使在项目结束后,接手团队仍然可以延续过程。项目描述文档可以让大的团队保持同步。特别是在开发复杂、大范围系统的项目中,作用至关重要,项目组织者必须搞好。下面我们提供一套根绝实际项目编写的通用项目文档模板。稍加修改,可适用于大部分技术项目。
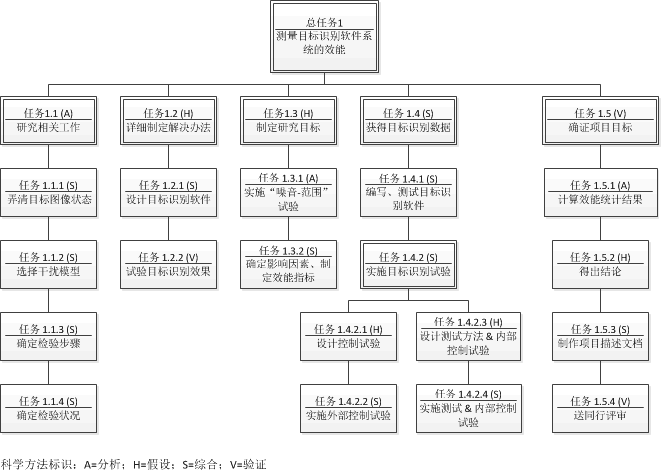
无论技术大小,开发的过程基本都是一样的。担当技术难度大、涉及的知识领域广、需要参与的团队大时,正确的项目设计、管理就尤为重要。科学的管理方法可以提高研发效率,减轻各部门的压力,处理意外情况。而贯穿于始终的就是“科学方法”,简论见本站另一则短文。这里我们提供一套项目流程样板供参考。这个样板是基于一个真实的目标识别项目修改后得到的。

技术开发,只要遵循统一的项目管理路线,无论多么庞杂、庞大,即使需要很复杂的过程、有很大的团队参与,也可以轻松完成。重要的是要在研发管理各个环节使用“科学方法”。 科学方法的简要框架可以概括为:

以下为一组贴心小提示, 帮助研发人员、工程师、项目管理人员和管理层更高效地完成研发任务。
提示
方便面是一种广受欢迎的快餐食品,市场上种类很多,商家竞争激烈。谁能快速推出一款广受欢迎的口味儿,谁就能抢占市场,在短期内收益颇丰。
但怎么才能调制出最受欢迎的料包哪?因为佐料选择多,配置比例不好掌握。各个地区,甚至各个季节顾客的口味也不一样,重口难调。这里我们将介绍一种快速、系统的配料筛选方法。通过调整各种调料组合,覆盖全部可能的组合空间;然后邀请品尝师打分,拟合统计预测模型,挑选出最受喜爱的调料配方。只要掌握了这种方法,经常使用,就能更快推出比对手更受欢迎的产品,永远立于不败之地。
这种配料筛选方法实际上是一种经典的试验设计方法,叫混料试验方法,在工业制造、高技术开发领域都在大显身手,世界最有竞争力的企业都在使用。但其原理其实并不复杂,如果使用开源的R软件来设计和分析,一般人都能掌握。所以我们希望借助方便面这个例子,帮助各位在科学技术开发中正确使用。
在混料试验设计中,独立因素是各个混料的百分比,各成分百分比之和一定是100%。影响整体混料特性的因素,不是哪个因素的多少,而是各种因素之间的比率。比如不锈钢的抗拉伸性,取决于不锈钢成分中的铁、铜、镍、铬之间的比率,而不是单一成分的多少。又如咱们的方便面料包,当面条和煮水量一定的情况下,味道取决于盐、鸡汤酱、酸菜、香油等调味品的比例,而不是某一调味品绝对量的多少。
由于各调味品的绝对取值受到限制,常见的选试验点的方法与正交试验不太一样, 用的是“单形格子”(Simplex-Lattice) 和“单形重心”(Simplex-Centroid) 选点法。如果部分因素之间还受到相互约束条件限制的话,就要用“D-最优极端定点”(D-Optimal Constrained Extreme-Vertices)设计法了。
当因素较多或约束条件较复杂时,手工选试验点会比较繁琐, 理解上也有困难。好在现在的开源免费的R软件,可以 帮我们完成这一步。本文也将讲解如何使用R来完成所有任务, 并在文尾提供数据、代码的下载。
那么我们怎么设计方便面料包的配料试验哪?
在面材和用水量固定的情况下,每袋方便面料包的总重量大体是固定的。因此影响方便面口味的因素是各个佐料的比例,而不是单一佐料的多少。比如做一款鸡汤口味的料包,主要成分是鸡汤酱、酸菜、盐和香油,影响汤的咸淡和酱香特点的是佐料的比例。现在市场上有的方便面不受顾客欢迎,被抱怨太清淡,盐太少,估计这位厂家就没使用我们的试验优化方法。
试验过程首先要设计各种配料比的组合,然后按配料比做出试验产品,交给品尝师品尝、打分。配料比的选择是设计的核心,如果选择不当,最后估测出的预测模型就会是错误的。试验次数的多少也要根据模型的复杂程度、限制条件、以及精确度来决定。试验点的选择要覆盖所有可能的选择区域,均匀分布。虽然手工做到这一点有点难,但我们可以请R软件帮忙。
输入限制条件后,R软件就能提供一套佐料配比试验计划。一共安排有16组试验。看一下限制区内试验点的分布情况。
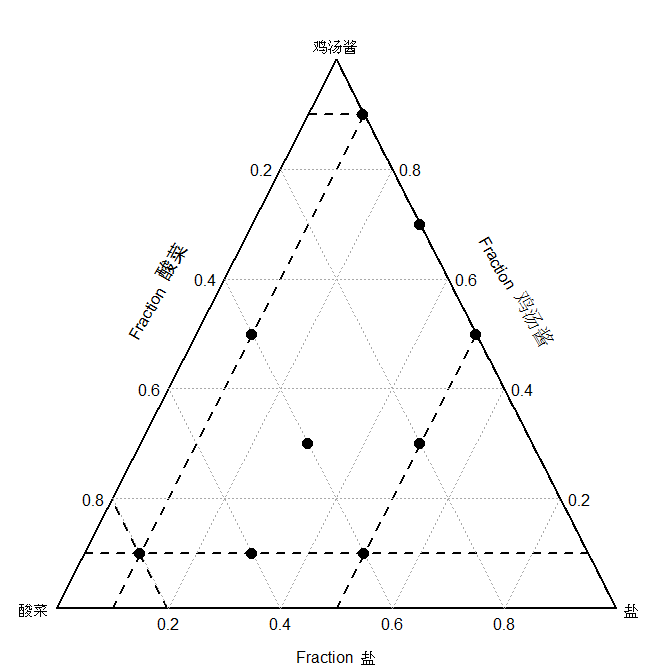
我们按这个计划做出方便面供十位品尝师排位打分。 我们用十位品尝师打出的平均分,来拟合以下典型二次多项式预测模型。用拟合好的这个模型,我们可以预测顾客对各种配料比的喜爱程度。看一下当香油确定在0的位址时,模型拟合好以后满意度排序得分预测结果。
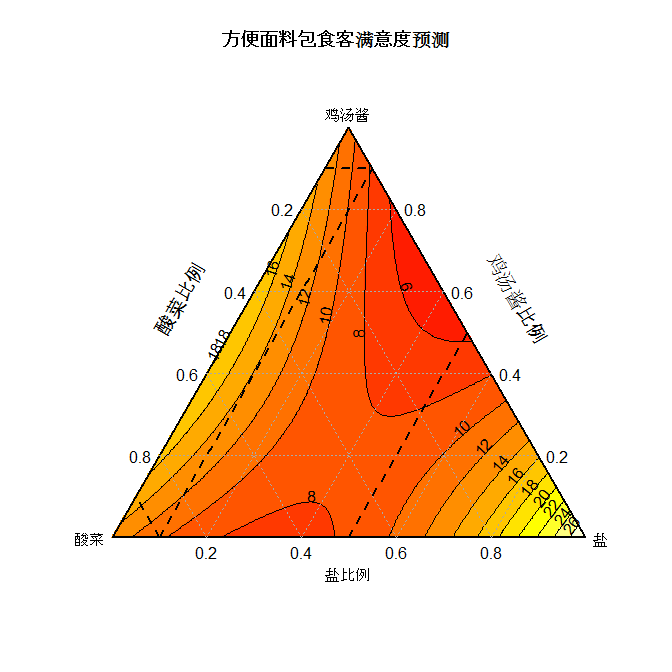
图中颜色愈深,排位分越靠前,越受欢迎。反之数越大,越不受欢迎。三个顶点对应的是鸡汤酱,酸菜和盐的含量,香油的比例固定在0的位置。在边线位置上是只有两种佐料组合的情况。中央虚线内为受约束可试验的区域。如果我们调整香油含量,就会看到预测的趋势也会相应地变化。(这里我们通过一个R/Shiny的应用演示此变化规律, 请参照文尾视频观看)。
下面介绍一下如何用R软件来实现以上过程。首先我们要引入三个功能库,”mixexp” 是专门用于设计和分析混料试验的。”nloptr” 是非线性方程优化功能库。”openxlsx” 是Excel文件编辑功能库。
第一步是设计混料试验。因为独立成分自身和之间都有约束条件,我们不能用“单形格子”和“重心”设计,也就是mixexp里面的SLD() and SCD() 功能。 我们需要用Xvert算法。好在mixexp提供了Xvert() 函数。 我们只要提供维数和约束条件,就能得到多维顶点坐标,很好用。
然后我们可以用DesignPoints()函数在三维坐标系中看一下选中的试验点。这些点都在约束区的棱边和顶点上。如需要拟合更高次的多项式, 我们可以用Fillv()函数,但试验次数也会增加,这里我们暂且就不考虑了。
第二步是分析试验数据。研究人员组织品尝师品尝16种配方,排序打分,输入数据。我们读入该数据,用mixexp里面的MixModel()函数拟合二次多项式模型,看一下拟和好的模型。预测的等高线图可以用ModelPlot()函数打出。 第三步就是寻找最佳配方了, 也就是在受约束条件下,相对于最高排名的各佐料比例。这要用到nloptr功能包里的nloptr()函数。写好优化目标,也就是我们拟合好的这个二次多项式,约束条件,相等的和不等的,然后执行nloptr()函数。再用ModelPlot()看一下在最优条件下的预测得分等高图。
最后最优的调味组合找到了。
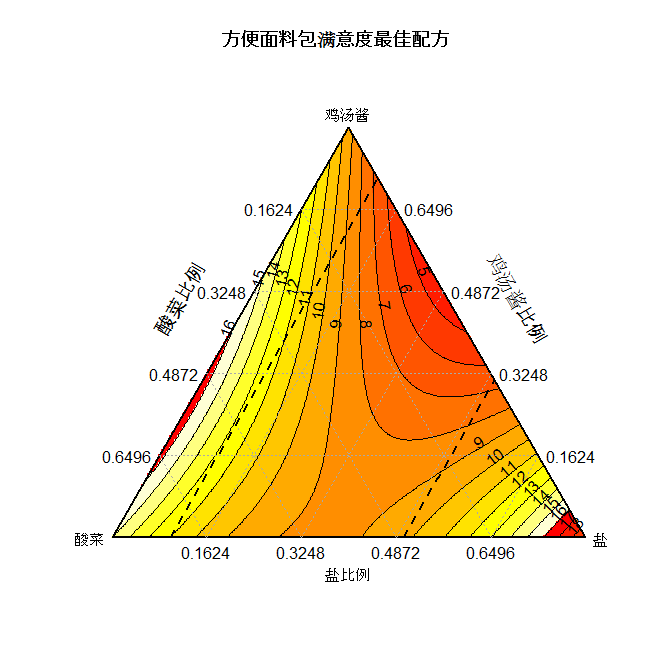
最佳满意度佐料配方组合是
在这个配料组合下,平均客户满意度会达到最高的3.4。有的人也许会问,为什么不用品尝师打最高分的那个组合哪?这是因为品尝师们本身会有局限性,与实际客户群会有偏差。用模型总体趋势估测的结果会有更广泛代表性, 同时兼顾其它不可控因素对顾客喜好产生的影响。
总结一下,我们通过16组混料设计试验,拟合了一个二次多项式模型,找到了喜爱度最高的调料比例组合。 我们使用R软件完成设计和模型估测以及非线性函数的最优化。这个试验原理和过程可以应用在所有工业生产、科技攻关领域, 是企业竞争力的倍增器。
本文中用到的和视频中提到的代码和数据都可在以下链接 下载, 并欢迎观看视频。要在攻关中快速实现突破,就要先掌握研究方法。从设计分析,到生产制造,零基础,学得会,我们介绍的方法适用于所有科研领域。欢迎与本公司联系,共同实现突破。
Watch live video
我今天介绍一种快书精准的仪器校准方法。通过用观测到的数据,对照真实值,拟合回归模型,估测矫正曲线,从而提高测量仪器的使用精准度。 我还将演示如何使用开源的R软件完成计算和作图。用到的所有数据和代码都可以在文后链接下载。
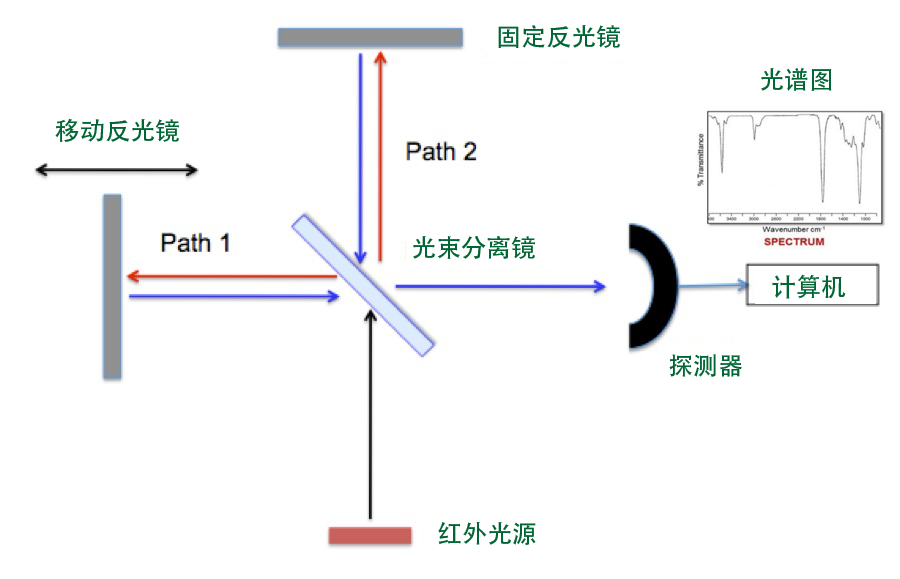
在制备纯硅晶用于生产集成电路时,碳原子会随机在硅晶体轴的两端形成,难于彻底清除。碳原子的多少会影响集成电路的性能,所以必须精确地测量出提炼出的硅晶中的碳含量,以便选择相应的处理方法。测量碳含量要用到的测量仪器叫傅立叶变换红外光谱仪,或FTIR光谱仪。 它的工作原理是根据被测量物质在红外光谱各个频段的吸收强度,判别某一种物质的含量。但由于精度要求极高,一般新仪器在使用前需要校准.
收集好的数据是这样的。左面是对一致碳含量的标准警惕样本,在FTIR侧联谊上测得的碳含量之,一共有五种含碳硅晶样本,覆盖一般常用范围,并侧重地碳含量,有A和B 两种地含量样本。每天每种测量五次。
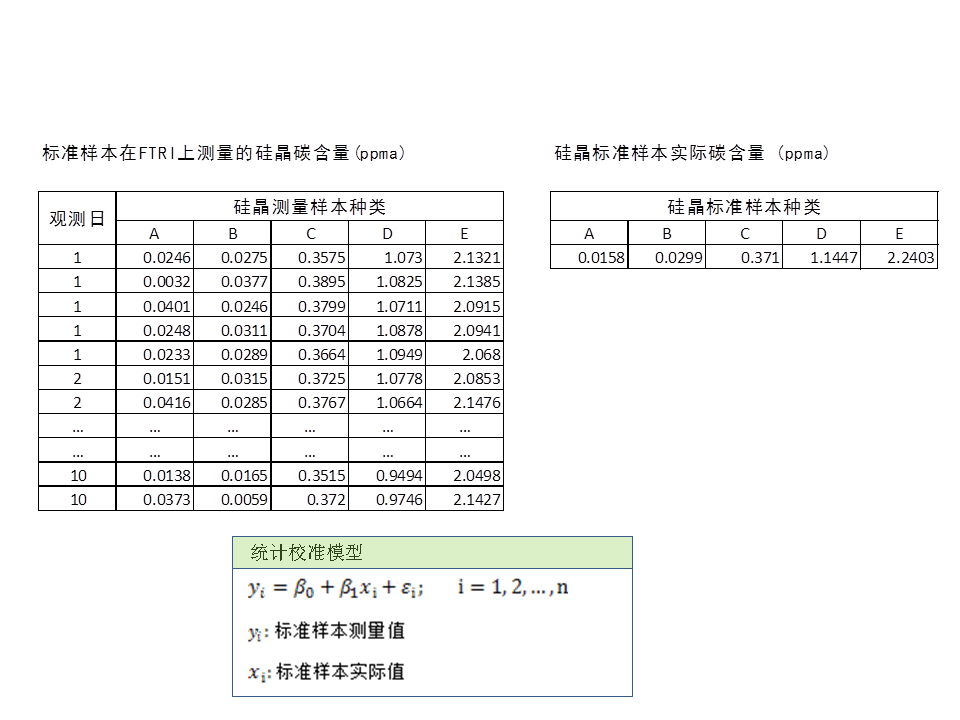
表中每行就是每一次测量样本获得的碳含量,每天,连续十天,一共50行数据。值得提到的是,控制图分析表明仪器供桌状态是受控的:所以这些数据时可以作为典型数据来用的。如果不受控的话,使用者应该先找到愿因,调整仪器,使其工作状态先受控。右面的标识样本一致的真实的碳含量。再看一下校准线的回归统计模型。其中相应变量Yi就是观测到的碳含量,Xi是样本真实碳含量,Ei 食宿及独立正态误差。 Beta0 和Beta1 是要估测的模型参数, 将用来调整光谱仪, 也可以用来直接用反回归法直接读取真实碳含量值。
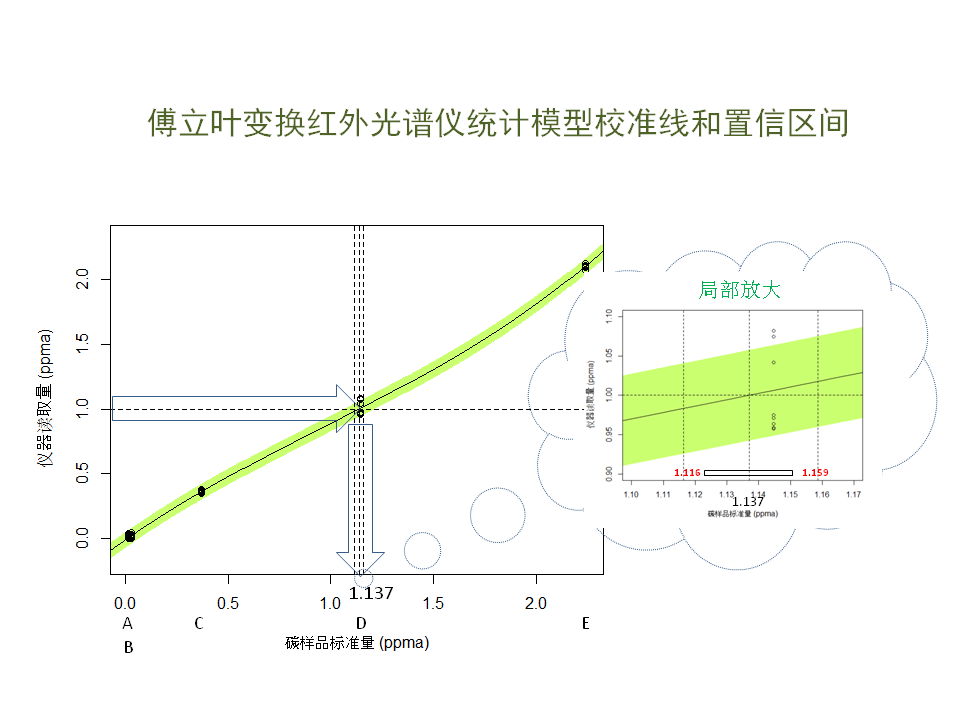
现在看一下拟合好的矫正曲线:纵轴是实际观测值,横轴是实际值,共有A, B, C, D, E五种硅晶样本。 为侧重地碳含量的精准度,用了两个低碳含量样本A和B。 你和实际与么中每天五个观测值得平均数。 最后选用的是三级多向时,与直线略微幼雏润,不大。绿色区域是95%置信区间带。
根据这个矫正模型,在实际使用中,如果读到一个值,比如1.0 PPMA, 那末相应的真实碳含量应该是多少哪?这就要用到一个模型方法叫逆拟合,也就是已知Y, 去求X,并给出X的置信区间。 这里X是一个统计变量,而不是常数。通过R语言的一个功能库, 我们计算出当Y=1时,相应的X, 也就是真实的碳含量应该是1.137, 95%的值行区间是介于1.116和1.159之间,也就是这台仪器实际上低估了真实的碳含量。我们可以依据这条假证曲线来推导未来的读取值。当然,另外一种方法就是调整正态仪器的功能参数,使校正曲线最大限度地接近45度直线。
我们可使用矫正曲线参数beta0 和beta1等直接调整测量仪,就更方便快捷了。
现在我们看一下如何通过R语言来完成模型拟合和画图。我之间主要节点演示一下,大家可在本文网址下载详细代码,阅读细节部分。 没有安装R和RStudio的可以在百度上搜,免费下载,并安装需要的功能库。
读入数据文件,处理成必要的R数据文件格式。
首先用R的基本功能你和一个单因素线性模型,叫Mod。 这个模型就是我们需要得到的矫正线。可以用plotFit()观看一下拟合好的情况。这里显示的是拟合好的矫正线及95%置信区间。 我们看到直线基本可以,但中间一组,也就是样本D组稍微偏低,似乎多项式曲线模型更合适一点。
下面我们选用一个三级多项式作为拟和模型。
依然用lm()功能,看一下拟合好后的结果。这个新模型与数据更接近一些。那末我们如何使用拟合好的曲线哪?比如说我们用光谱仪观测到硅晶的碳含量是1.0 PPMA,也就是Y的值,要知道真实的碳含量,我们可以依据校正曲线反向找X的值。用R功能库里的Invest()功能可以一步完成。只要引用拟合好的Mod模型,设置Y0 为1.0,我们看到,X是1.136981, 以及95%置信区间。我们还可以在图上画出位置来。
其它代码细节可在本频道网址下载后查看。
我们顺利地建立了红外光谱仪的矫正曲线,探明了观测值和实际值的关系,并可以在未来的使用过程中获得更精准的测量值。在试验之前要注意的是, 为保证收集到的数据的有效性,必须用控制图方法,确认收集到的数据符合均值和范围变量稳定可控的统计特征。具体方法请参考有关文献或关注本频道。
科学技术是提高产品竞争力的法宝。量化分析方法可以加快研发速度。希望大家关注本网,今后会有更多技术量化分析方法介绍。大家可在以下链接下载代码和数据。
下载数据和R代码:
我们平常做工农业实验,最忌讳的就是盲目选择实验点,或者一次只改变一个变量。因为如果要验证的因素很多的话,所要做的是实验会成倍增加, 浪费财力物力不说,还可能找不到需要的因果关系。另外一个要注意的是,试验要分步进行,逐步添加试验。不要一上来就做全因子实验。 因为不是所有因素都和输出变量有紧密关系的。也就是说,最好把实验分为两步做,既 可以节省原材料和工作时间, 又可以精确命中目标。第一步是筛选实验,用部分因子实验从众多因素中筛选出比较重要的几个。第二步是优化实验,为筛选出来的几个因素寻找选最佳工作区间。大家经常听说的中心组合试验设计,和Box-Bhnken 等响应面试验就是常用的优化实验设计。
好的实验设计,要能做到用尽可能少的试验次数,准确地发现各因素的主作用,交互作用以及如何影响相应变量的。
今天我要演示的是集成电路硅晶圆加工过程的一个实际案例。我们知道在硅晶片加工中有一个重要步骤,就是硅晶片表面的氧化刻蚀工序。目前,无论多么高端的硅晶片,无论多么复杂的2D, 3D纳米级集成线路结构,都要经过硅晶氧化刻蚀这道工序。
具体来讲,就是通过光刻机在硅晶片表面把电子线路的反光膜刻出痕迹后,暴露下面的二氧化硅层,再刻蚀二氧化硅层。刻蚀二氧化硅层要用很精密的仪器,因为二氧化硅层只有5-20纳米。一个纳米是一毫米的百万分之一,所以 非常非常的薄,肉眼一般无法看见。不同颜色的硅晶片,就是由不同厚度的表面氧化层反光频率不同造成的。刻蚀硅氧化层有干和湿两种刻法,目前比较通用的是干刻法。干刻法须把硅晶片放入一个封闭的金属室中。晶片放在一个旋转的托盘上, 氮气,氮气和水汽的混和气体被吹入封闭的室内,并吹入氟化氢气体,根据时间的长短控制刻蚀的深度。刻蚀机性能好坏的一个重要指标就是在晶片表面刻蚀的均匀度, 或一致性。均匀一致性越高,生产出来的芯片的质量就越好,良品率就越高。下面我们设计一组试验来验证一台新300mm硅晶片刻蚀机的均匀一致性水平,并找出最佳的工作区间。
现有研究表明,影响刻蚀机一致性有六个可能因素,分别为;
A: 托盘转速 (高 : +1,低: -1)
B: 灼蚀前氮气和氮水混合气总气流量 (高 : +1,低: -1)
C: 灼蚀前水气雾流量 (高 : +1,低: -1)
D: 氮气和氮水混和气总气流量 (高 : +1,低: -1)
E: 灼蚀气体流速 (高 : +1,低: -1)
F: 氧化硅灼蚀厚度 (200 Angs.: +1, 50 Angs.: -1)
要得知被影响的一致性, 一般先要在圆晶表面选九个点,测量晶片每个点在刻蚀氧化层之前和之后高度的差。然后再用九个差的标准差除以其平均值,再取对数,就得到一致性。这个也就是统计学中经常提到的变异系数的对数。测量厚度要用极精密的仪器,因为氧化层一般只有几个纳米, 一毫米的百万分之一。
六个因素,因为每值只取高和低,全因子试验要做2^6=64个试验, 这是很多的试验,而且会浪费很多昂贵的硅晶片。但实际情况,不是所有因素都一定与一致性相关,所以 我们可以先用部分因子试验筛选出几个比较重要的,然后再集中研究这几个重要的因素。部分因子试验可以比全因子试验成倍地减少试验次数,这样我们既筛选了因素,又能优化过程,很经济划算。
现在我演示一下如何用R软件设计这个实验。R软件是免费开源的,可以在百度上搜并下载。R的软件包几乎可以设计和分析任何类型的试验, 所以推荐大家学习。
我们要先引入两个功能库,FrF2和daewr。后面分析还会用到另外 几个,具体请参考详细代码, 可以在片后网址下载。
我们需要设计一个解析度四级的试验,以保证精确度,2^(6-2)=16 个的部分因子设计就可以。主因子混淆关系用E=ABC and F=BCD,因为三个因子的交互基本可以忽略不计,所以用这种混淆可以保证E和F的可靠性,E和F是比较重要的因子。
现在看一下设计好的试验计划。这个计划可以存为EXCEL文件,研究人员可以拿去做试验并记录数据。看一下因素混淆结构,只有二次混淆,一级主因素都清楚的。再看一下一和二级的主因素相关分析图,一级之间都是白的,也就是0; 二级交互因素之间有部分混淆, 因为是部分因子设计。但如果是全因子设计,级交互因素也都是清晰的。
再在试验中心加上两个中心点,用来估测纯测量误差,最后一共18个试验点。
试验做好输入均匀一致性数据后,我们还用R来分析结果。拟合主因素加二级交互的模型,我们应注意到只有部分二级交互作用可以估测到, 其它的未估测到的,是和估测到的混淆在一起的。所以要搞清这些显著的二级交互作用到底是哪个, 按常规至少要再加做16 个试验,也就是翻倍。但我们注意到混淆的结构,其实再做8个,也是翻一半倍就够了。 只要把含有A, E, 和F的二级交互解开即可。圆晶很贵,时间也宝贵,所以再加八个当然比加16个好了。但如果不受财力限制,多做16个试验也可以。多做会提高一点精度。
用R软件再加八个试验,然后做试验,收集数据,把数据重新引入R,拟合模型,我们看到 原来混淆的二级交互估测值已经清楚了。显著相关的两个主因素是E: 灼蚀气体流速 ,和F: 氧化硅灼蚀厚度(含5 nano meter 和20 nano meter两个种类),交互作用包括,A:F, B:C, 和稍微弱一点E:F。
这是在最佳取值位二维的试验结果和拟和线。纵轴是刻蚀一致性,数值越小一致性越好。横轴是因素位值从低到高。 这里我们看到, 在其它因素都取最佳值时,因素E,刻蚀气体流速与刻蚀的一致性成正比。所以刻蚀气体流速越高,刻蚀的一致性就越好。因素F取低值-1,也就是刻蚀5纳米厚的氧化层时,刻蚀的一致性要好于刻蚀高值位, +1,也就是20纳米厚时。
在交互作用方面,在试验取值范围内,因素A: 托盘转速 和F: 氧化硅刻蚀厚度有交互影响。具体就是,对于刻蚀厚度在5纳米厚度时,托盘转速越高一致性越好。 但当刻蚀厚度在20纳米厚度时,托盘转速越低一致性越好。同样,因素B: 刻蚀前氮气和氮水混合气总气流量,和因素C:刻蚀前水气雾流量 也有交互作用。也就是,当刻蚀前水气雾流量高的时候,刻蚀前混合气总气流量越高,反应一致性越好。相反,当刻蚀前水气雾流量低的时候,刻蚀前混合气总气流量越低,反应一致性越好。 同样,我们也会看到因素E和F也存在这种相对微弱一点的交叉关系, 即虽然刻蚀气体流速越高,一致性越好,但在刻蚀层薄的5纳米刻蚀改进程度要好于厚层的20纳米,也就是刻蚀气体对薄层刻蚀的影响率大于对厚层刻蚀的影响率。
综合各种因素,根据前后共24个试验拟合好的统计模型,我们知道了在什么情况下,刻蚀的一致性达到总体最好,也就是本机器各操作相关系数最佳的取值点。这是实际生产过程中重要的一步, 对提高半导体集成电路芯片的质量至关重要。
通过演示这个实例,我向大家介绍了如何使用部分因子试验做因素筛选,并按需要扩展试验点的方法。我们还一同了解了如何用开源的R软件设计和分析试验,搞清了几个机器设置参数与刻蚀一致性的关系。
欢迎大家观看根据本文制作的视频。点击以下链接,下载本文用到的R相关代码。
Click link below to download a text file containing the R codes used in the article.
资格认证的目的是提高生产过程和设备的效能。通过统计学方法描述和量化生产过程和设备的运行特征,成为资格认证成败的关键。
资格认证程序由三个阶段构成, 阶段一, 建立过程和设备基线;阶段二, 描述过程特征并优化, 确认其稳定性;阶段三,改进设备的可靠性,展示可制造性和竞争力。要完成每一阶段,都要用到一些重要的统计学方法。在进一步介绍如何使用统计学方法之前, 我们在本文中首先了解一下资格认证的每一个阶段及要达到的目标。下图显示的是资格认证各级段的流程图。
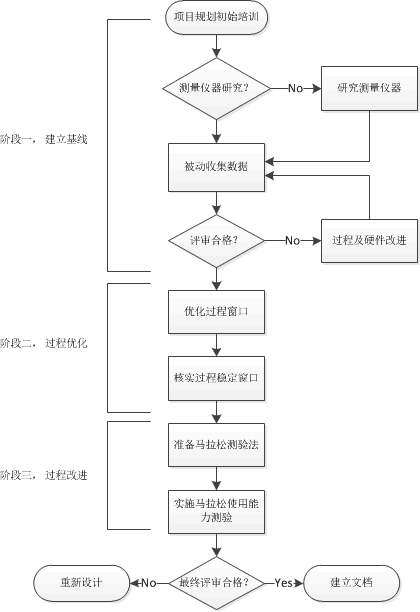
阶段一, 建立过程和设备基线。
测量仪器, 测量系统, 过程和设备的效能
这是第一步,主要完成项目规划和商业运作相关内容。项目成员和客户要制定项目要达到的目标和为达到目标所需要的资源。内容包括:具体分列最后要完成的目标;数据收集的方法;结果如何发布;用以衡量成功与否的基线。开始对测量系统、生产设备、软件使用的培训,并持续贯穿于整个项目执行的全过程。
测量仪器容量测试的目的是保证测量工具能够完成需要的测量任务。保证持续不断的稳定性、准确性,测量值和实际值高度接近。测量数值的变化率保持在对特定目标测量允许的变动范围之内,同时意料之外的工具特征也受到统计过程控制限制。项目中的每一件测量工具都要经过测量仪器容量测试。接下来的博文中会逐段介绍几个基于统计学方法的实例。
变化性的根源, 评估取样设计, 建立连续的稳定性,
阶段二, 描述过程特征并优化, 确认其稳定性。
阶段三,改进设备的可靠性,展示可制造性和竞争力。
摩托罗拉铁人方案,生产过程、工艺、软件 可靠性改进测试方案, 又称夜间设备可靠性改进计划。通过对设备极限使用, 即连续不停1000小时以上保持设备在极限端运转,模拟真实生产场景,观测并发现软、硬件出现的各种问题。一般是白天对制造流程故障溯源,提出并实施改进方案;夜间极端运转流程,观测,记录各种故障。为提高效率,工厂一般是一边实施铁人方案,一边在实际生产过程中使用改进成果。
马拉松方案,一种通过模拟真实使用状态,对设备使用效率量化的方法。 一般24小时不停,连续运转几个星期, 记录每次检修间隔的平均时长、中值、变化率等统计数字,从而推算设备在实际生产过程中的效能,以及对硅晶生产增加的成本。这种方法还可以用来检测硬件和软件的可靠性, 及早制定应对方案。
产品质量和技术含量是企业生存的基础. 无论企业的大小都是如此. 一般认为要提高核心竞争力, 企业需要很大的投入. 事实却是如此. 但企业家不要因此而忽视了身边一些可以立刻改进提高的操作方法. 这些方法不需要很大投入却可以取得很明显的效果. 在即将发表的这个系列的文章中, 我们将集中介绍一些量化产品生产要素的方法, 帮助企业家在短时间内提高产品市场竞争力. 请广大客户集中关注.
本系列介绍的方法集中在以下四个角度:
Outline: A quick summary of the Qualification Plan, how statistical methods fit in each of the three stages of the Qualification Plan, with actual case reference, and quick insight/discussion on the contribution of statistical methods. Focusing on the substantiated contribution (vs. unverified, theoretical suppositions) of each of the statistical methods.
Relevance of Statistical Methods in Manufacturing: Even in today’s high-tech manufacturing environment with very precise measurements and powerful processing capabilities arising from the advanced technologies, the demand for stricter equipment baseline settings, the discovery of new processing techniques to solve emerging problems, a thorough understanding of the process and equipment capacities, as well control of the high-tech manufacturing process is still relevant. For the majority of industries and do not employ high precision equipment, traditional statistical methods should live strong and well for a long time.
Three areas that we focus on to achieve immediate impacts for tech businesses are:
We will discuss the ways to statistical methods that would improve each of the three areas with actual case examples. In the case example, we will emphasize how the statistical methods accelerate the efforts, make impossibles possible, saved expenses and deliver better products. Below is a diagram of an ideal manufacturing qualification plan should look like, each of the three stages involves many of the statistical techniques we will discuss in this sequence of articles.