前言
方便面是一种广受欢迎的快餐食品,市场上种类很多,商家竞争激烈。谁能快速推出一款广受欢迎的口味儿,谁就能抢占市场,在短期内收益颇丰。
但怎么才能调制出最受欢迎的料包哪?因为佐料选择多,配置比例不好掌握。各个地区,甚至各个季节顾客的口味也不一样,重口难调。这里我们将介绍一种快速、系统的配料筛选方法。通过调整各种调料组合,覆盖全部可能的组合空间;然后邀请品尝师打分,拟合统计预测模型,挑选出最受喜爱的调料配方。只要掌握了这种方法,经常使用,就能更快推出比对手更受欢迎的产品,永远立于不败之地。
这种配料筛选方法实际上是一种经典的试验设计方法,叫混料试验方法,在工业制造、高技术开发领域都在大显身手,世界最有竞争力的企业都在使用。但其原理其实并不复杂,如果使用开源的R软件来设计和分析,一般人都能掌握。所以我们希望借助方便面这个例子,帮助各位在科学技术开发中正确使用。
混料试验设计简介
在混料试验设计中,独立因素是各个混料的百分比,各成分百分比之和一定是100%。影响整体混料特性的因素,不是哪个因素的多少,而是各种因素之间的比率。比如不锈钢的抗拉伸性,取决于不锈钢成分中的铁、铜、镍、铬之间的比率,而不是单一成分的多少。又如咱们的方便面料包,当面条和煮水量一定的情况下,味道取决于盐、鸡汤酱、酸菜、香油等调味品的比例,而不是某一调味品绝对量的多少。
由于各调味品的绝对取值受到限制,常见的选试验点的方法与正交试验不太一样, 用的是“单形格子”(Simplex-Lattice) 和“单形重心”(Simplex-Centroid) 选点法。如果部分因素之间还受到相互约束条件限制的话,就要用“D-最优极端定点”(D-Optimal Constrained Extreme-Vertices)设计法了。
当因素较多或约束条件较复杂时,手工选试验点会比较繁琐, 理解上也有困难。好在现在的开源免费的R软件,可以 帮我们完成这一步。本文也将讲解如何使用R来完成所有任务, 并在文尾提供数据、代码的下载。
料包的配料试验
那么我们怎么设计方便面料包的配料试验哪?
在面材和用水量固定的情况下,每袋方便面料包的总重量大体是固定的。因此影响方便面口味的因素是各个佐料的比例,而不是单一佐料的多少。比如做一款鸡汤口味的料包,主要成分是鸡汤酱、酸菜、盐和香油,影响汤的咸淡和酱香特点的是佐料的比例。现在市场上有的方便面不受顾客欢迎,被抱怨太清淡,盐太少,估计这位厂家就没使用我们的试验优化方法。
试验过程首先要设计各种配料比的组合,然后按配料比做出试验产品,交给品尝师品尝、打分。配料比的选择是设计的核心,如果选择不当,最后估测出的预测模型就会是错误的。试验次数的多少也要根据模型的复杂程度、限制条件、以及精确度来决定。试验点的选择要覆盖所有可能的选择区域,均匀分布。虽然手工做到这一点有点难,但我们可以请R软件帮忙。
输入限制条件后,R软件就能提供一套佐料配比试验计划。一共安排有16组试验。看一下限制区内试验点的分布情况。
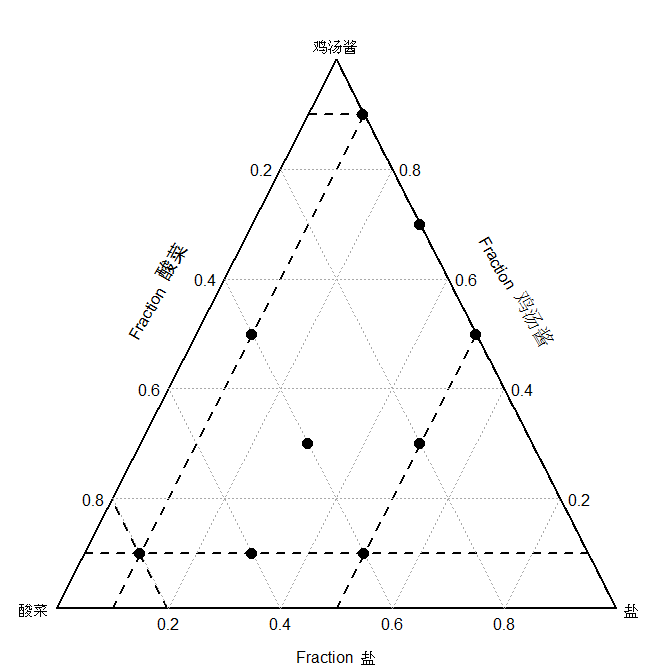
我们按这个计划做出方便面供十位品尝师排位打分。 我们用十位品尝师打出的平均分,来拟合以下典型二次多项式预测模型。用拟合好的这个模型,我们可以预测顾客对各种配料比的喜爱程度。看一下当香油确定在0的位址时,模型拟合好以后满意度排序得分预测结果。
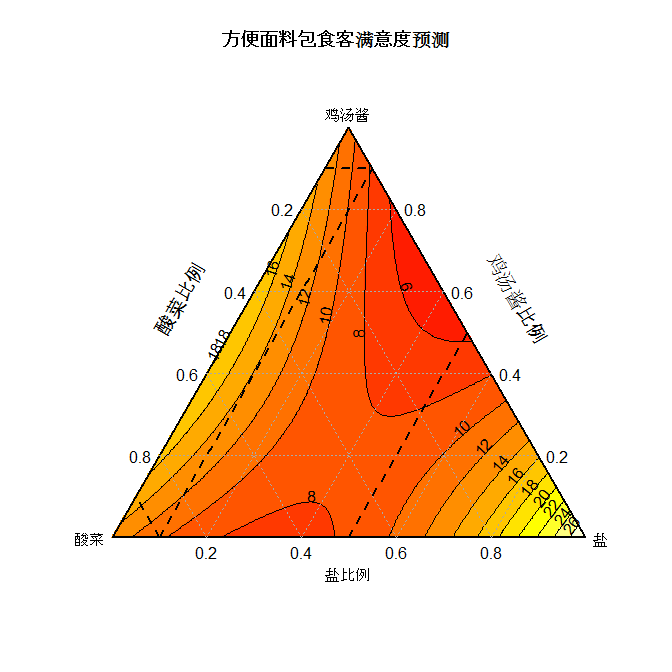
图中颜色愈深,排位分越靠前,越受欢迎。反之数越大,越不受欢迎。三个顶点对应的是鸡汤酱,酸菜和盐的含量,香油的比例固定在0的位置。在边线位置上是只有两种佐料组合的情况。中央虚线内为受约束可试验的区域。如果我们调整香油含量,就会看到预测的趋势也会相应地变化。(这里我们通过一个R/Shiny的应用演示此变化规律, 请参照文尾视频观看)。
在R软件中实现混料设计数据分析
下面介绍一下如何用R软件来实现以上过程。首先我们要引入三个功能库,”mixexp” 是专门用于设计和分析混料试验的。”nloptr” 是非线性方程优化功能库。”openxlsx” 是Excel文件编辑功能库。
第一步是设计混料试验。因为独立成分自身和之间都有约束条件,我们不能用“单形格子”和“重心”设计,也就是mixexp里面的SLD() and SCD() 功能。 我们需要用Xvert算法。好在mixexp提供了Xvert() 函数。 我们只要提供维数和约束条件,就能得到多维顶点坐标,很好用。
然后我们可以用DesignPoints()函数在三维坐标系中看一下选中的试验点。这些点都在约束区的棱边和顶点上。如需要拟合更高次的多项式, 我们可以用Fillv()函数,但试验次数也会增加,这里我们暂且就不考虑了。
第二步是分析试验数据。研究人员组织品尝师品尝16种配方,排序打分,输入数据。我们读入该数据,用mixexp里面的MixModel()函数拟合二次多项式模型,看一下拟和好的模型。预测的等高线图可以用ModelPlot()函数打出。 第三步就是寻找最佳配方了, 也就是在受约束条件下,相对于最高排名的各佐料比例。这要用到nloptr功能包里的nloptr()函数。写好优化目标,也就是我们拟合好的这个二次多项式,约束条件,相等的和不等的,然后执行nloptr()函数。再用ModelPlot()看一下在最优条件下的预测得分等高图。
预测最优结果
最后最优的调味组合找到了。
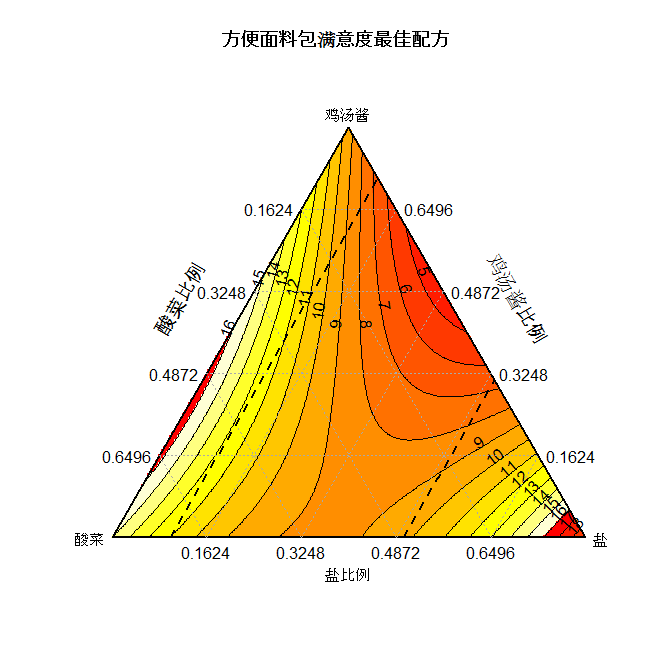
最佳满意度佐料配方组合是
- 鸡汤酱= 0.51
- 酸菜= 0
- 盐= 3
- 香油 = 19
在这个配料组合下,平均客户满意度会达到最高的3.4。有的人也许会问,为什么不用品尝师打最高分的那个组合哪?这是因为品尝师们本身会有局限性,与实际客户群会有偏差。用模型总体趋势估测的结果会有更广泛代表性, 同时兼顾其它不可控因素对顾客喜好产生的影响。
总结一下,我们通过16组混料设计试验,拟合了一个二次多项式模型,找到了喜爱度最高的调料比例组合。 我们使用R软件完成设计和模型估测以及非线性函数的最优化。这个试验原理和过程可以应用在所有工业生产、科技攻关领域, 是企业竞争力的倍增器。
本文中用到的和视频中提到的代码和数据都可在以下链接 下载, 并欢迎观看视频。要在攻关中快速实现突破,就要先掌握研究方法。从设计分析,到生产制造,零基础,学得会,我们介绍的方法适用于所有科研领域。欢迎与本公司联系,共同实现突破。
Watch live video