我今天介绍一种快书精准的仪器校准方法。通过用观测到的数据,对照真实值,拟合回归模型,估测矫正曲线,从而提高测量仪器的使用精准度。 我还将演示如何使用开源的R软件完成计算和作图。用到的所有数据和代码都可以在文后链接下载。
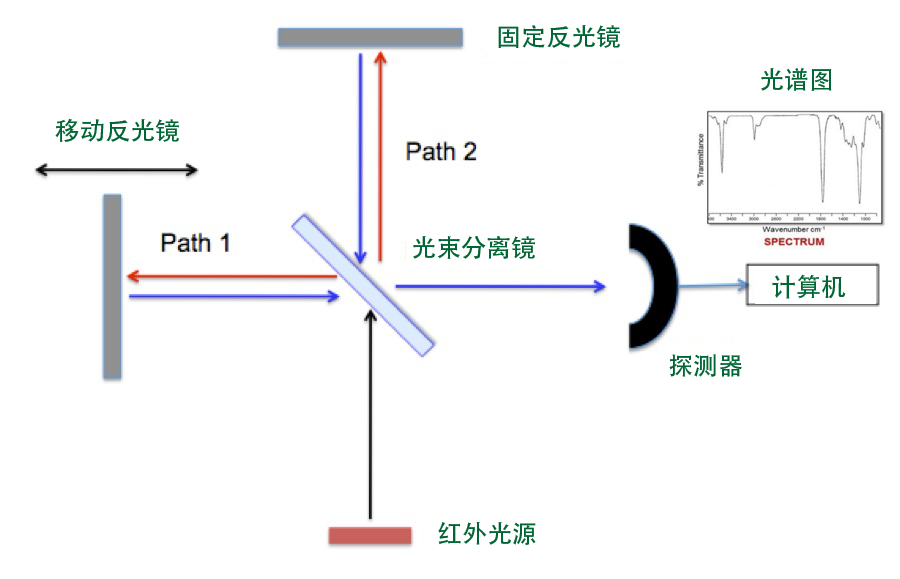
在制备纯硅晶用于生产集成电路时,碳原子会随机在硅晶体轴的两端形成,难于彻底清除。碳原子的多少会影响集成电路的性能,所以必须精确地测量出提炼出的硅晶中的碳含量,以便选择相应的处理方法。测量碳含量要用到的测量仪器叫傅立叶变换红外光谱仪,或FTIR光谱仪。 它的工作原理是根据被测量物质在红外光谱各个频段的吸收强度,判别某一种物质的含量。但由于精度要求极高,一般新仪器在使用前需要校准.
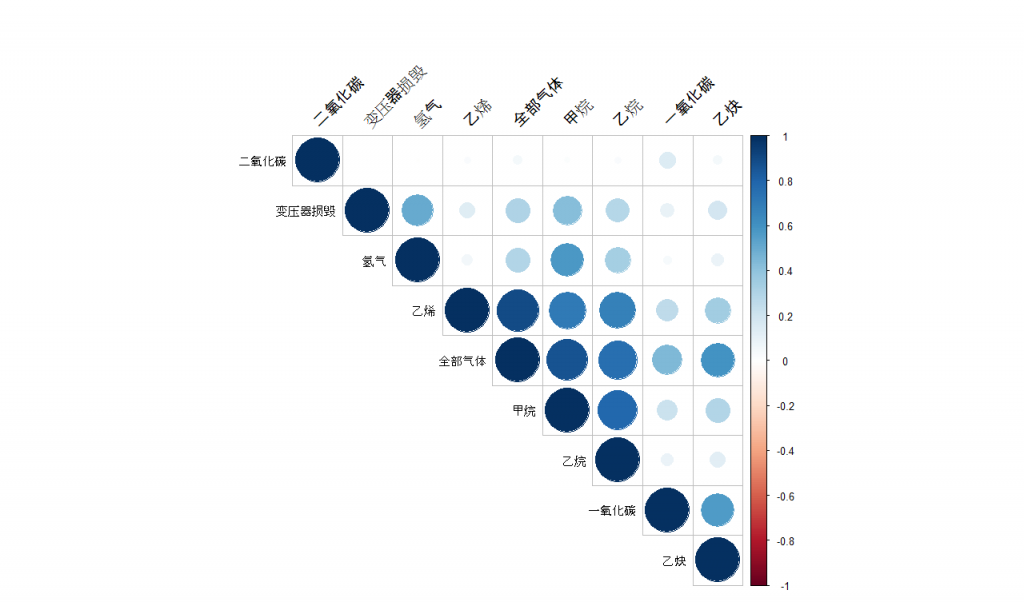
收集好的数据是这样的。左面是对一致碳含量的标准警惕样本,在FTIR侧联谊上测得的碳含量之,一共有五种含碳硅晶样本,覆盖一般常用范围,并侧重地碳含量,有A和B 两种地含量样本。每天每种测量五次。
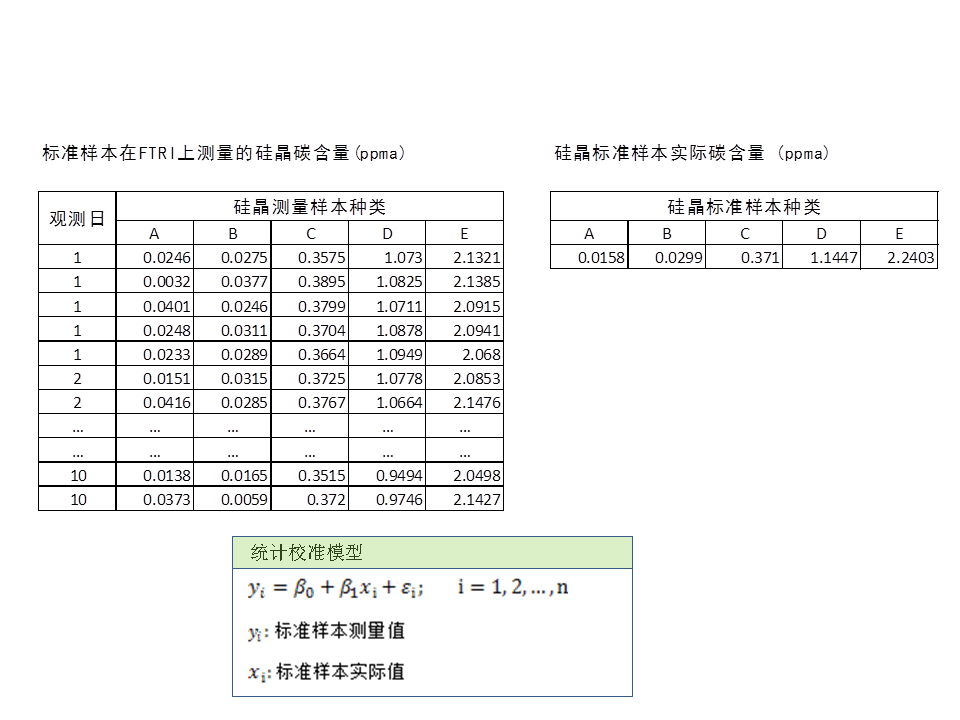
表中每行就是每一次测量样本获得的碳含量,每天,连续十天,一共50行数据。值得提到的是,控制图分析表明仪器供桌状态是受控的:所以这些数据时可以作为典型数据来用的。如果不受控的话,使用者应该先找到愿因,调整仪器,使其工作状态先受控。右面的标识样本一致的真实的碳含量。再看一下校准线的回归统计模型。其中相应变量Yi就是观测到的碳含量,Xi是样本真实碳含量,Ei 食宿及独立正态误差。 Beta0 和Beta1 是要估测的模型参数, 将用来调整光谱仪, 也可以用来直接用反回归法直接读取真实碳含量值。
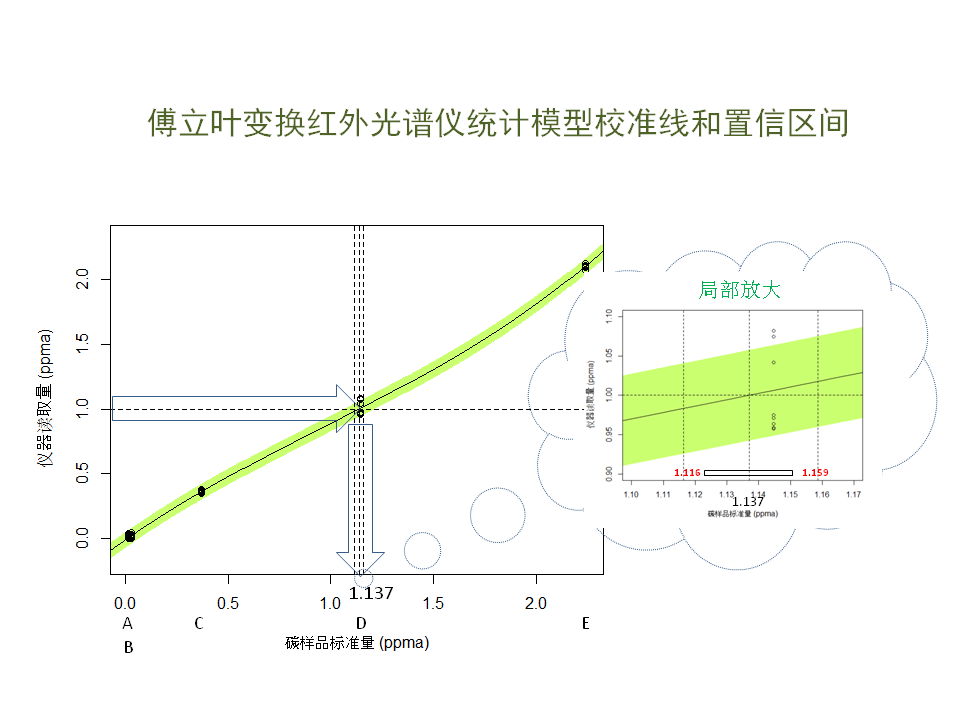
现在看一下拟合好的矫正曲线:纵轴是实际观测值,横轴是实际值,共有A, B, C, D, E五种硅晶样本。 为侧重地碳含量的精准度,用了两个低碳含量样本A和B。 你和实际与么中每天五个观测值得平均数。 最后选用的是三级多向时,与直线略微幼雏润,不大。绿色区域是95%置信区间带。
根据这个矫正模型,在实际使用中,如果读到一个值,比如1.0 PPMA, 那末相应的真实碳含量应该是多少哪?这就要用到一个模型方法叫逆拟合,也就是已知Y, 去求X,并给出X的置信区间。 这里X是一个统计变量,而不是常数。通过R语言的一个功能库, 我们计算出当Y=1时,相应的X, 也就是真实的碳含量应该是1.137, 95%的值行区间是介于1.116和1.159之间,也就是这台仪器实际上低估了真实的碳含量。我们可以依据这条假证曲线来推导未来的读取值。当然,另外一种方法就是调整正态仪器的功能参数,使校正曲线最大限度地接近45度直线。
我们可使用矫正曲线参数beta0 和beta1等直接调整测量仪,就更方便快捷了。
现在我们看一下如何通过R语言来完成模型拟合和画图。我之间主要节点演示一下,大家可在本文网址下载详细代码,阅读细节部分。 没有安装R和RStudio的可以在百度上搜,免费下载,并安装需要的功能库。
读入数据文件,处理成必要的R数据文件格式。
首先用R的基本功能你和一个单因素线性模型,叫Mod。 这个模型就是我们需要得到的矫正线。可以用plotFit()观看一下拟合好的情况。这里显示的是拟合好的矫正线及95%置信区间。 我们看到直线基本可以,但中间一组,也就是样本D组稍微偏低,似乎多项式曲线模型更合适一点。
下面我们选用一个三级多项式作为拟和模型。
依然用lm()功能,看一下拟合好后的结果。这个新模型与数据更接近一些。那末我们如何使用拟合好的曲线哪?比如说我们用光谱仪观测到硅晶的碳含量是1.0 PPMA,也就是Y的值,要知道真实的碳含量,我们可以依据校正曲线反向找X的值。用R功能库里的Invest()功能可以一步完成。只要引用拟合好的Mod模型,设置Y0 为1.0,我们看到,X是1.136981, 以及95%置信区间。我们还可以在图上画出位置来。
其它代码细节可在本频道网址下载后查看。
我们顺利地建立了红外光谱仪的矫正曲线,探明了观测值和实际值的关系,并可以在未来的使用过程中获得更精准的测量值。在试验之前要注意的是, 为保证收集到的数据的有效性,必须用控制图方法,确认收集到的数据符合均值和范围变量稳定可控的统计特征。具体方法请参考有关文献或关注本频道。
科学技术是提高产品竞争力的法宝。量化分析方法可以加快研发速度。希望大家关注本网,今后会有更多技术量化分析方法介绍。大家可在以下链接下载代码和数据。
下载数据和R代码: