The main goal of text analytics is to answer these five main questions:
- Which terms and phrases are most common?
- In what context are terms and phrases used?
- Which terms tend to appear together? How an I group similar documents together and explore them?
- What are the recurring themes (topics) within the corpus?
- How can I reduce the dimension of the text data, so I can use the information in a predictive model?
Friendly user interface makes such analysis much faster, as specific knowledge on language process algorithm is not required, especially for non-data -specialists. Expertise from other knowledge area in this way is faster combined with text-analytic techniques that provide a powerful knowledge discovery route.
1. Term and Phrases that are Most Common
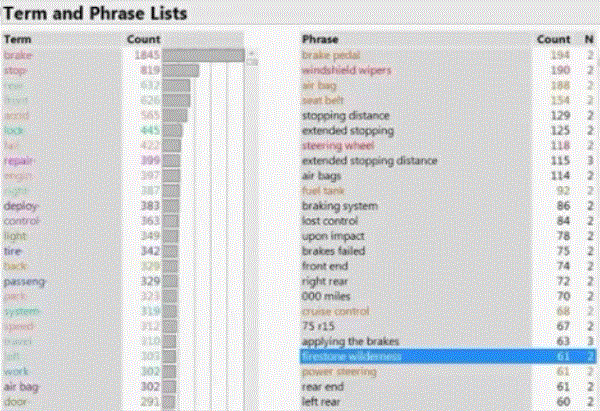
Terms shown in orange are statistically created to reflect the similarity of a group of terms.
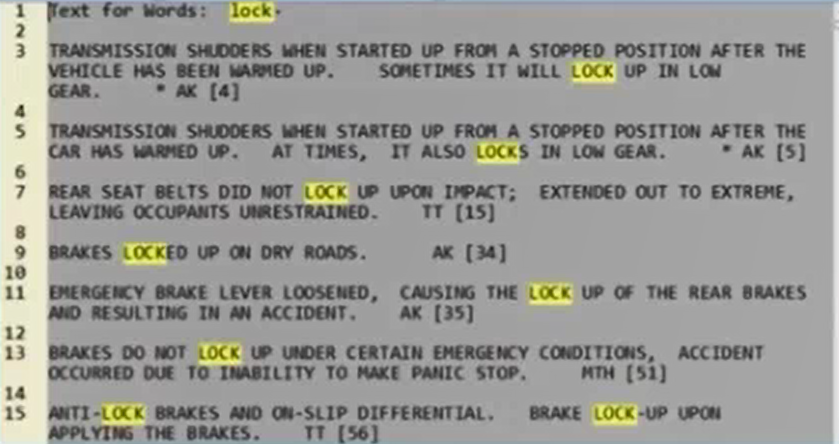
2. The Context in Text the Most Frequent Terms and Phrases are Used
3. Terms or Documents Tend to Appear Together
The “wordcloud” is a popular visual summary of the major theme of a body of text. Below is a word cloud constructed based on text in this blog homepage:

Terms or phrases in one document may also be clustered to fewer natural groups, as shown below:
Terms or phrases within one cluster may be explored in the Word Cloud, to see how significant these are within the entire document.

Similarly, this may be done to cluster similar documents based on the terms or phrases that are dominant within each document.
4. The Recurring Theme (Topics) in a Document
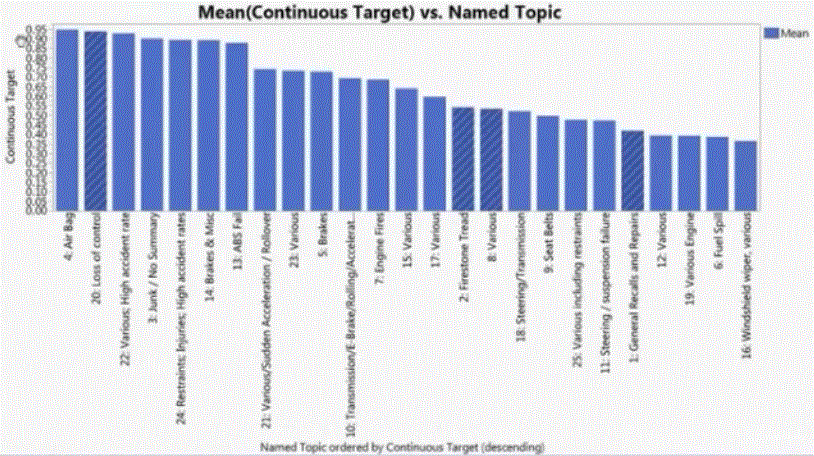
The terms grouped with in the topic provide a sense of the issue. Ranking of the terms tells user which topics are more important.
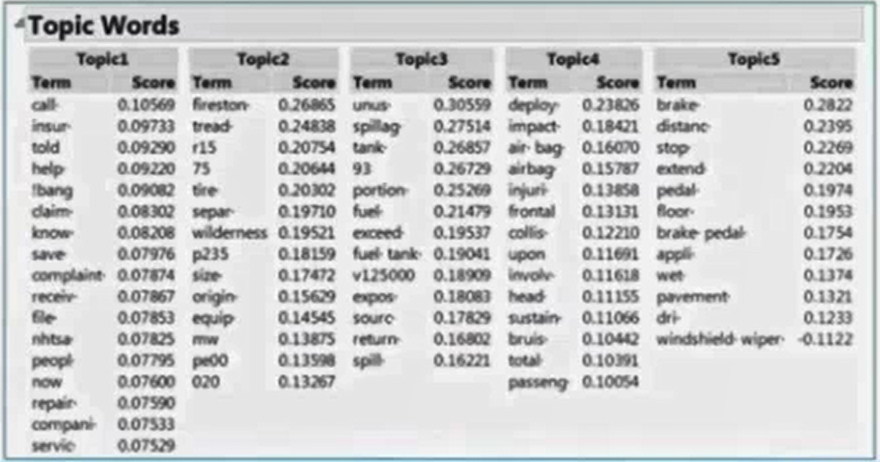
5. Singular Vector of Terms and the Predictive Power added to Prediction Models
Texting mining is mostly dimension reduction techniques of text data by associating words or phrases that appear in corpus. The build both descriptive and predictive models based on the reduced dimensions for understanding of the under cause or predicting future outcome.
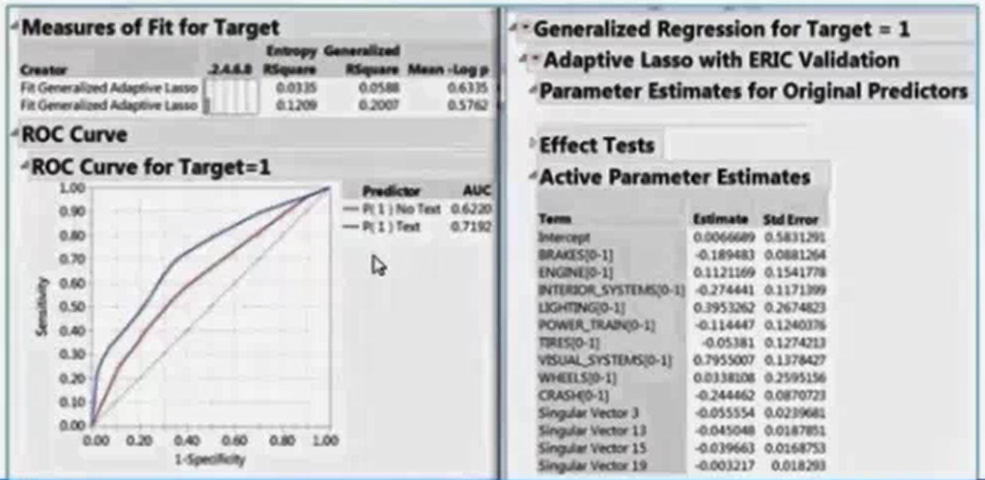
Regression models may be conducted adding the singular vectors constructed based on the term and phrases in the documents. The top curve is the ROC curve shows the lift from the including of additional singular vectors, shown near the bottom right, upon using only the regular predictors, the second ROC from the top.
Reviewing Concepts
Useful R packages for text analytics: R Packages ‘RcmdrPlugin.temis’ is a visual driven fast-result Text Analytics tool. As of June 2018 it is of Version 0.7.10. This ‘R Commander’ plug-in providing an integrated solution to perform a series of text mining tasks such as importing and cleaning a corpus, and analyses like terms and documents counts, vocabulary tables, terms co-occurrences and documents similarity measures, time series analysis, correspondence analysis and hierarchical clustering. Corpora can be imported from spreadsheet-like files, directories of raw text files, ‘Twitter’ queries, as well as from ‘Dow Jones Factiva’, ‘LexisNexis’, ‘Europresse’ and ‘Alceste’ files. The package provides different functions to summarize and visualize the corpus statistics. Correspondence analysis and hierarchical clustering can be performed on the corpus. Functions frequentTerms to list the most frequent terms of a corpus, specificTerms to list terms most associated with each document, subsetCorpusByTermsDlg to create a subset of the corpus. Term frequency, term co-occurrence, term dictionary, temporal evolution of occurrences or term time series, term metadata variables, and corpus temporal evolution are among the other very useful functions available in this package for text mining. R has a very rich set of analytic tools for text mining, though much in-depth knowledge may needed if one would like to become expert, these packages are summarized at here. (2017-11) A basic quick summary may be found here (2017-12)
Text analytics helps to discover original contents based on terms grouped in one cluster, and the story buried within. The capability of showing the text by clicking on the cluster is nice. Below text window displays all sentences of the words grouped within one cluster listed on lower left corner.

Text analytics is not just exploratory, with no significance measure or validation of results. It can also be used to linear models to understand the driving factor for certain outcomes. The “topics” summarized by the text analytics may be used as covariate variables, in the way principal components were used in certain regression analysis. So it is a dimension reduction technique. See the application example at the end.
Research Terms
Corpus: written texts, especially the entire works of a particular author or a body of writing on a particular subject, “the Darwinian corpus”. For software tools it is a collection of text documents, stored in a single data table column.
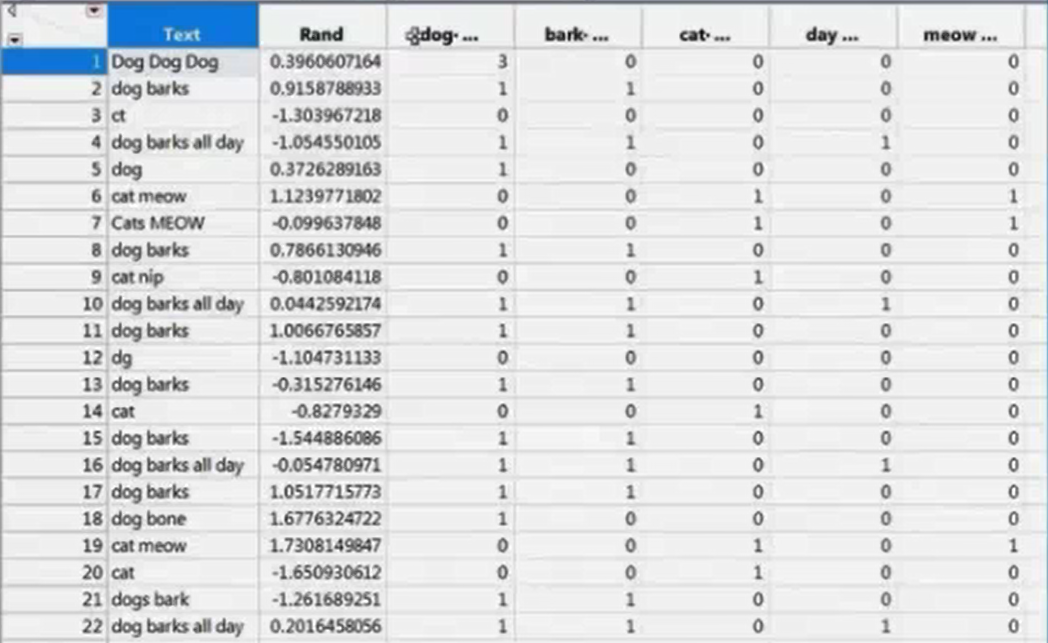
DTM (Document Term Matrix): A sparse matrix where columns correspond to terms, and rows correspond to documents. When a given document contains a given term, the corresponding cell is nonzero. There are several ways to assign values to non-zeros cells.
Tokenizing: The process of breaking a document into terms and phrases. Some software tool has functionalities for tokenizing that is also customization.
Stop Word: A term to be excluded from analysis. Software needs to have a built-in stop list which can be customized as desired.
Stemming: Treating terms with the same root as the same term. Example: “run”, “run” and “running” become “run”. Software needs to stem terms automatically, while also supporting customized exceptions.
TF IDF, the text analysis weighing term. Others are: Binary, Ternary, Frequency, Log Frequency
The way the terms are clustered
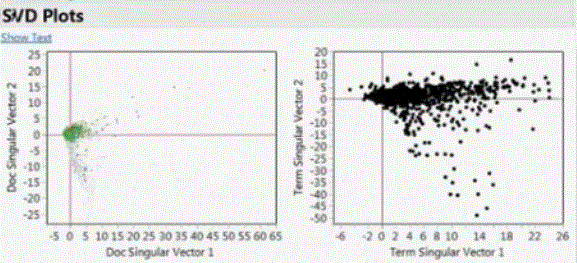
Latent Semantics Analysis, is the singular value decomposition (SVD) of the document and term matrix. SVDs account for most of the variability in the text, 80% of the SVDs are sufficient to almost all information
A “topic” is constructed. Topic formula can be saved for modeling. Clusters and latent classes can be constructed as categorical predictor, and singular vectors for continuous predictors.
Application Example
Analyzing car repair shop customer survey, to understand the car mechanical issues that made repair shop customers to change to a different manufacturer (churn rate) for their next car. Comment section of the customer survey is free expression section, car mechanic problem diagnostics are also free texts descriptions written by mechanics. Customer were as it they will change manufacturer, which is a Yes/No response. Final generalized model, used SVDs derived from text analytics of the customer and mechanics text descriptions as control variables. Each of SVD may be focused on certain aspects about how well the car was performing on.
(Analyzing Text Patterns and Modeling Text)